Power Query: Falsche Datentypen? Drei Tipps, die das verhindern
Es sollte mal wieder schnell gehen und dabei bleib das Festlegen der Datentypen auf der Strecke. Doch spätestens beim nächsten Datenimport rächt sich das. Denn unsachgemäß eingestellte oder bei erneuten Importen nicht überprüfte Datentypen erhöhen das Risiko von Fehlern und Datenverfälschungen. Hier zwei typische Beispiele:
1) In der Abfrage wurden die Datentypen sauber definiert: der Spalte mit der Mengenangabe wurde Ganze Zahl zugewiesen. Beim Import der nächsten Monatsdaten enthält die Spalte mit den Mengenangaben plötzlich Werte mit Dezimalstellen. Die werden automatisch abgeschnitten, da Ganze Zahl eingestellt ist. Eine Verfälschung der Daten ist die Folge.
2) Für die Spalte Menge wurde Ganze Zahl festgelegt, aber beim nächsten Import stehen in der Spalte Menge solche Einträge wie 1 Kiste oder 1 Karton. Das hat Fehler zur Folge, die das Aktualisieren der Daten behindern.
Dies zeigt, dass die Kontrolle der Datentypen in zwei Schritten erfolgen muss: 1) beim Aufbau der Abfrage und 2) beim Import neuer Daten. WIE das geht, zeige ich in diesem Beitrag.
![Datentyp beim Erstellen der Analyse gezielt einstellen [1] und beim Update kontrollieren [2]](https://www.office-kompetenz.de/wp-content/uploads/2025/08/1_FalscheDatentypen.png)
Datentyp beim Erstellen der Analyse gezielt einstellen [1] und beim Update kontrollieren [2]
Power Query: Spalten entfernen ja, aber bitte richtig
Kürzlich hatte ich im Kurs eine spannende Diskussion zum Entfernen von Spalten. Die Frage war: Was tun, wenn sich nach dem Entfernen mehrerer Spalten herausstellt, dass es eine zu viel war? Den Abfrageschritt löschen? Oder lässt der sich nachträglich noch bearbeiten?
Meine Antwort: „Kommt drauf an“! Nämlich darauf, WIE die Spalten entfernt wurden. Das klingt vielleicht ein wenig rätselhaft, aber keine Sorge, ich erkläre es gleich.
Spalten entfernen, aber welche ist die beste Methode?
Power Query: Berechnungen für eine variable Anzahl von Spalten – so bleiben Abfragen flexibel!
Wer mit Daten arbeitet, stößt mitunter auf folgende Herausforderung: eine sich ändernde Anzahl von Spalten soll dynamisch verarbeitet werden. Beispielsweise kommen wöchentlich oder monatlich neue Spalten hinzu. Wie lässt sich da eine effiziente Abfrage finden, die ohne manuelle Anpassungen auskommt?
Power Query bietet auch dafür eine Lösung. In diesem Blogbeitrag zeige ich, wie sich Spalten gleichen Typs in Power Query automatisiert addieren lassen, und zwar unabhängig davon, wie viele Spalten es gerade sind.
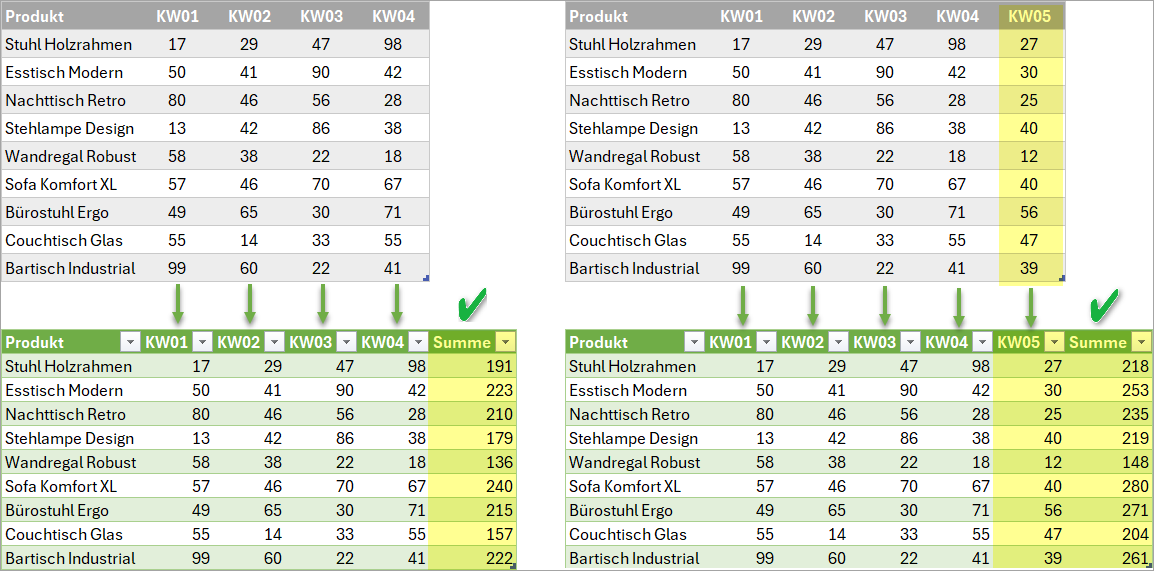
Neu hinzukommende Kalenderwochen sollen automatisch in die Summe einbezogen werden
Sollten Excel-Einsteiger »Power Query« lernen?
Bisher hätte ich diese Frage eher mit Nein beantwortet. Doch dann kam letzte Woche dieser Excel-Einstiegskurs: Dort berichteten 4 von 7 Teilnehmern, dass sie nicht mit Excel arbeiten und es auch nicht nutzen würden, wenn da nicht diese CSV wäre.
Bei weiterer Nachfrage kam heraus: wöchentlich muss eine CSV-Datei bearbeitet werden:
– zuerst die Angaben zum Datum in Ordnung bringen,
– dann die Daten nach einem Kriterium filtern,
– die verbleibenden Daten nach Datum sortieren,
– eine Multiplikation durchführen und
– abschließend eine überflüssige Spalte löschen.
Diese stupide Arbeit steht jede Woche an und es darf nichts vergessen werden.
Meine Reaktion? Ich zeigte, wie diese fünf Aufgaben von Power Query erledigt werden. Und, dass diese Aufbereitungsschritte beim nächsten Mal in kürzester Zeit durchgeführt werden, indem nur der Befehl Aktualisieren aufgerufen wird. Das Erstaunen bei den Teilnehmern war sichtbar, und sie wollten Power Query lernen.
In diesem Power Query Rezept #24 beschreibe ich, WIE es geht.

Die Daten der CSV-Datei filtern, sortieren, berechnen und das Ergebnis in einer Excel-Tabelle anzeigen
Power Query: Böse Überraschungen beim Runden vermeiden
Was ergibt sich, wenn die Zahl 2,5 gerundet wird? Excel liefert mit der Funktion RUNDEN das Ergebnis 3, Power Query hingegen 2.
Der Grund dafür: In Power Query wird bei Werten genau in der Mitte zwischen zwei ganzen Zahlen standardmäßig auf die nächste gerade Zahl auf- oder abgerundet. Aus 2,5 wird somit 2, aus 1,5 wird ebenfalls 2.
Wie Power Query beim Runden tickt und wie es auf kaufmännisches Runden umgestellt werden kann, beschreibe ich in diesem Rezept.

Zum Teil unterschiedliche Ergebnisse beim Runden in Excel und Power Query
Power Query: Weniger Datenlast durch automatisches Ausschließen irrelevanter Spalten
Bei Datenbeständen mit technischen Angaben habe ich schon oft erlebt, dass zahlreiche Spalten nur temporär gebraucht werden oder für die Auswertung nicht von Belang sind. Solche Spalten haben beispielsweise Präfixe wie Sys_oder Tmp_ oder User_.
Um die Datenlast zu reduzieren, sollten solche nicht benötigten Spalten bei der Analyse ausgeschlossen werden.
Doch wie lässt sich das in Power Query automatisieren und wie lassen sich gezielt unnötige Spalten ermitteln? In diesem Power Query Rezept zeige ich, wie mit einer Änderung im M-Code solche Spalten automatisch entfernt werden, ohne die Spaltennamen direkt anzusprechen!

Spalten mit dem Präfix Sys_ automatisch von dem zu analysierenden Datenbestand ausschließen
Power Query: Störende null-Werte ersetzen und somit korrekte Berechnungen sicherstellen
Fehlende Werte – sog. null-Werte – sind oft der Grund, dass Berechnungen gar nicht oder nicht korrekt erfolgen können. In meinem Blogbeitrag Power Query: Falsche Ergebnisse bei leeren Zellen vermeiden habe ich erklärt, wie beim Addieren und Subtrahieren von Zahlen sichergestellt wird, dass auch Zellen mit null korrekt berechnet werden – in dem Fall mit Hilfe der Funktion List.Sum.
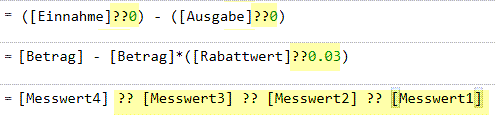
Im heutigen Blogbeitrag zeige ich, wie mit Hilfe des COALESCE-Operators ?? störende null-Werte auf einfache Art behandelt werden. Die vielfältige Verwendbarkeit des COALESCE-Operators demonstriere ich anhand von drei Beispielen: 1) Ermitteln des Saldos von Einnahmen und Ausgaben, 2) Berechnen eines rabattierten Betrags und 3) Auswerten von Messreihen.
Power Query ohne Chaos: Abfragen effizient dokumentieren
Wer kennt das nicht: Bereits nach wenigen Tagen erinnert man sich kaum noch daran, warum ein bestimmter Schritt in eine Power Query-Abfrage eingebaut wurde oder wozu eine spezielle Hilfsabfrage dienen soll. Noch schlimmer: Jemand verlässt das Team und hinterlässt einen Dschungel unkommentierter Abfragen. Wie lässt sich jetzt der Ablauf von Abfragen herausfinden oder gar ändern?
Die Lösung heißt Dokumentation. Doch mal ehrlich: Wer macht das schon gern? Daher zeige ich hier drei Methoden, wie das möglichst mühelos gelingt.

Power Query: Falsche Ergebnisse bei leeren Zellen vermeiden
Neulich bei einem bekannten Getränkehersteller: Im Kurs überrascht mich jemand mit der Frage, warum Power Query nicht fehlerfrei subtrahieren könne. Allerdings stellte sich schnell heraus, was die tatsächliche Ursache für falsche Ergebnisse war: Zellen ohne Inhalt, die in Power Query mit null angezeigt werden.
Was ist an null so besonders? Wird beispielsweise von einem Ausgangswert eine null-Zelle subtrahiert, gibt Power Query null zurück statt des Ausgangswertes. Das führt zu Fehlern, wenn der Rückgabewert null in weiteren Berechnungen verarbeitet wird. Mit den folgenden Schritten lassen sich solche Fehler vermeiden.

Bei null in einer Zelle rechnen die Operatoren Plus (+), Minus (-), Mal (*) oder Geteilt durch (/) nicht, sondern geben null zurück
Power Query: Duplikate eliminieren durch Gruppieren und Aggregieren und Informationen erhalten
Power Query wird oft genutzt, um Informationen aus einer Zelle zu trennen und auf verschiedenen Zeilen oder Spalten zu verteilen. Doch manchmal wird genau das Gegenteil gebraucht. Diesmal muss ich Inhalte aus mehreren Zeilen in einer Zelle zusammenfassen:
- Und zwar sind links in der grauen Originaltabelle die Artikel wegen verschiedener Herkunftsländer mehrfach aufgelistet.
- Ich benötige jedoch eine Übersicht, in der alle Artikel nur einmal stehen.
- Die Herkunftsländer sollen in einer Zelle als Zusatzinformation zusammengefasst werden.

Links die Artikelliste mit Duplikaten, rechts die Liste nach ArtikelNr gruppiert und die Herkunftsländer in einer Zelle gebündelt
![]()